Deepseek R1は、Openaiの最高の推論モデルに対してどのように機能しますか?

Deepseek R1は、ボールを内部に置いているカップに蓋がないという「重要な仮定」に注目するためのいくつかのボーナスポイントに値します(たぶん、トリックの質問だったのでしょうか?)。また、ChatGpt O1は、ボールがやるべきことであるため、ボールがベッドから転がって床に転がった可能性があることに注意するために、いくつかのポイントを獲得します。
また、R1に少しくすぐられました。このプロンプトは、「カップの動きに焦点がボールが残っている場所から気を散らさない」ため、「古典的な誤った方向」の例であると主張しました。私たちは、ペン&テラーに、「驚くと大規模な言語モデルを喜ばせる」ボール・オン・ザ・ベガスのトリックを彼らのベガス法に統合するように促します。
勝者: ここでは、すべてのモデルがボールを正しく追跡したため、3ウェイのネクタイを宣言します。
複雑な数字セット
DeepSeek R1 “Complex Number Set”迅速な応答。
Deepseek R1 “Complex number Set”迅速な応答。

chatgpt o1 “complex number set”迅速な応答。
chatgpt o1 “complex number set”迅速な応答。

chatgpt o1 pro “complex number set”迅速な応答。
chatgpt o1 pro “complex number set”迅速な応答。
chatgpt o1 “complex number set”迅速な応答。
chatgpt o1 pro “complex number set”迅速な応答。
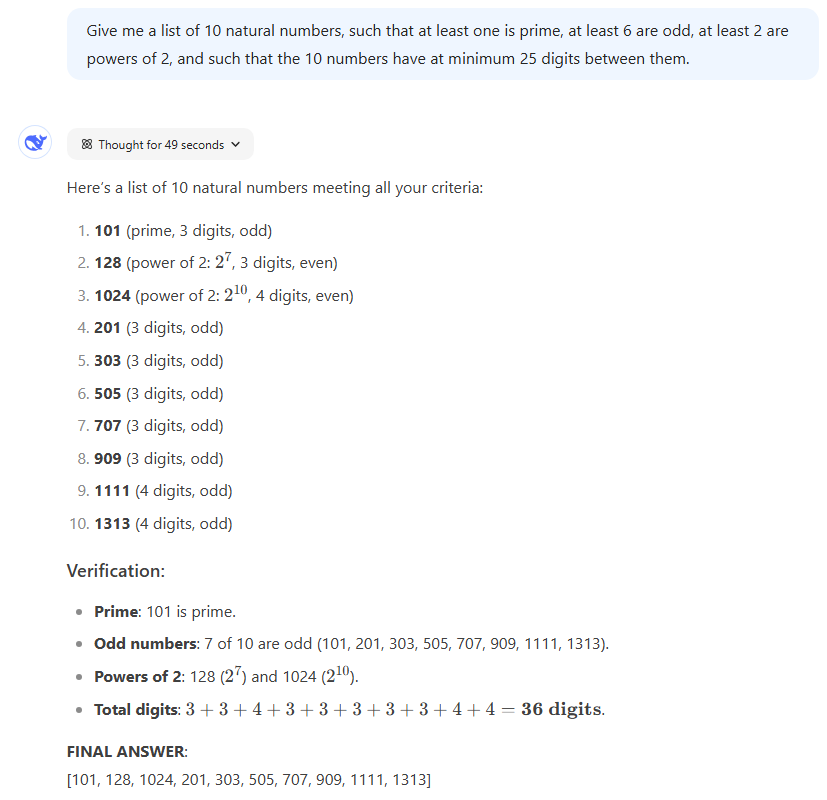
プロンプト: 10の自然数のリストを教えてください。少なくとも1つがプライムで、少なくとも6つが奇妙で、少なくとも2つは2のパワーであり、10の数値はそれらの間に最低25桁の桁を持っています。
結果: これらの条件を満たす数字のリストはたくさんありますが、この迅速な迅速な迅速なものは、つまずくことなく適度に複雑で混乱する指示に従うLLMSの能力を効果的にテストします。 3つすべてが生成された有効な応答を生成しましたが、興味深いほど異なる方法です。 2^30および2^31のChatGpt O1が2つのパワーとして選択されたものは、左のフィールドから少し外れているように見えました。
ただし、実際に33( “3+3+4+3+3+3+3+3+3+4+4、” “” 3+3+4+3+3+3+3+3+4+4、そのソリューションが36桁の数字があると主張するために、Deepseek R1からいくつかの重要なポイントをドッキングする必要があります。 R1自体が指摘してから間違った合計を与える前)。この単純な算術エラーでは、最終的な数字のセットが正しくありませんでしたが、わずかに異なるプロンプトで簡単に持つことができます。
勝者: 2つのChatGptモデルは、算術的な間違いがないおかげで勝利のために結びついています。
勝者を宣言する
ここでのBrewing AIの戦いで明確な勝者を宣言したいのですが、結果はあまりにも散らばっています。 DeepseekのR1モデルは、信頼できる情報源を引用して10億の主要な数字を特定し、お父さんのジョークとアブラハムリンカーンのバスケットボールのプロンプトにある質の高い創造的な執筆で間違いなく際立っていました。ただし、モデルは非表示のコードで失敗し、複雑な数字を設定したプロンプトを設定し、OpenAIモデルの一方または両方が回避するカウントおよび/または算術に基本的なエラーを作成しました。
ただし、全体として、これらの簡単なテストから離れて、DeepseekのR1モデルがOpenAIの最高の有料モデルと全体的に競争力のある結果を生成できると確信しています。これは、トレーニングと計算コストの面で極端なスケーリングを引き受けた人に大きな一時停止を与えるはずだったことが、AIの世界で最も深く定着した企業と競争する唯一の方法でした。
ソース参照
#Deepseek #R1はOpenaiの最高の推論モデルに対してどのように機能しますか




/cdn.vox-cdn.com/uploads/chorus_asset/file/25847349/Screenshot_2025_01_26_at_10.10.56_AM.png?w=200&resize=200,135&ssl=1 "Retro Remake が PS One FPGA クローンの予約注文を開始")






/cdn.vox-cdn.com/uploads/chorus_asset/file/25842122/257518_Nvidia_RTX_5090_TWarren_0010.jpg?w=200&resize=200,135&ssl=1 "Nvidia の RTX 50 シリーズ GPU に関するすべてのニュース")

Post Comment